
Aldous Huxley (1937) regarded the decentralization of industry and government necessary for a better society. Norbert Wiener’s insights (1950) into the dynamics and ethics of humans and large computer systems hinted at the advantages. Marshall McLuhan (1962) anticipated a shift from the centralized mechanical age to the decentralized electronic age, coining the term global village as shorthand for such a welcome outcome. E.F. Schumacher (1973) considered decentralization allied with freedom and one of “the truths revealed by nature’s living processes”. Steven Levy’s hacker ethic (1984) includes the tenet “mistrust authority – promote decentralization”. And Nicholas Negroponte (1995) regards decentralization as one of the four cardinal virtues of the information society (alongside globalization, harmonization and empowerment).
When centralization is mediated by an organization, governmental or corporate, its best interests must be aligned perfectly and continuously with the parties subject to its gravity in the mediating context – otherwise decentralization must be preferred to avoid the appropriation and erosion of those parties' valuable agency. Importantly, decentralization demands decentralization at every level without exception for any exception would be centralization. By definition.
This post aims to scope the challenge that still lies ahead to secure decentralization even with the rise and rise of cryptonetworks such as Ethereum. For more information about decentralization in general and why it's important, see Decentralization – a deep cause of causes you care about deeply, written for the World Wide Web Foundation.
The Internetome
UPDATE July 2021: see https://internetome.org/
In computing, a set of network layers that work together is often referred to as a stack eg, the OSI Reference Model. Each layer is designed with a particular purpose in mind and interacts directly with the layers immediately above and below, metaphorically speaking.
Stacks are a useful construct to conceptualize a system. In seeking to do the same for the topic of decentralization in the context of people and digital networks, I wanted to identify the main things – for want of a better word – involved. I call it the Internetome, a repurposing of the name I gave an Internet of Things conference I designed and hosted in 2010. It incorporates the suffix -ome used to denote the object of a biological field of study (eg, genome, interactome, connectome, biome).
The Internetome evolved naturally into a circular rather than columnar form. Here's how I portray it and each vertex is discussed briefly below. I don't consider it set in stone but more of a thinking device that will undoubtedly adapt based on the criticism it might attract.
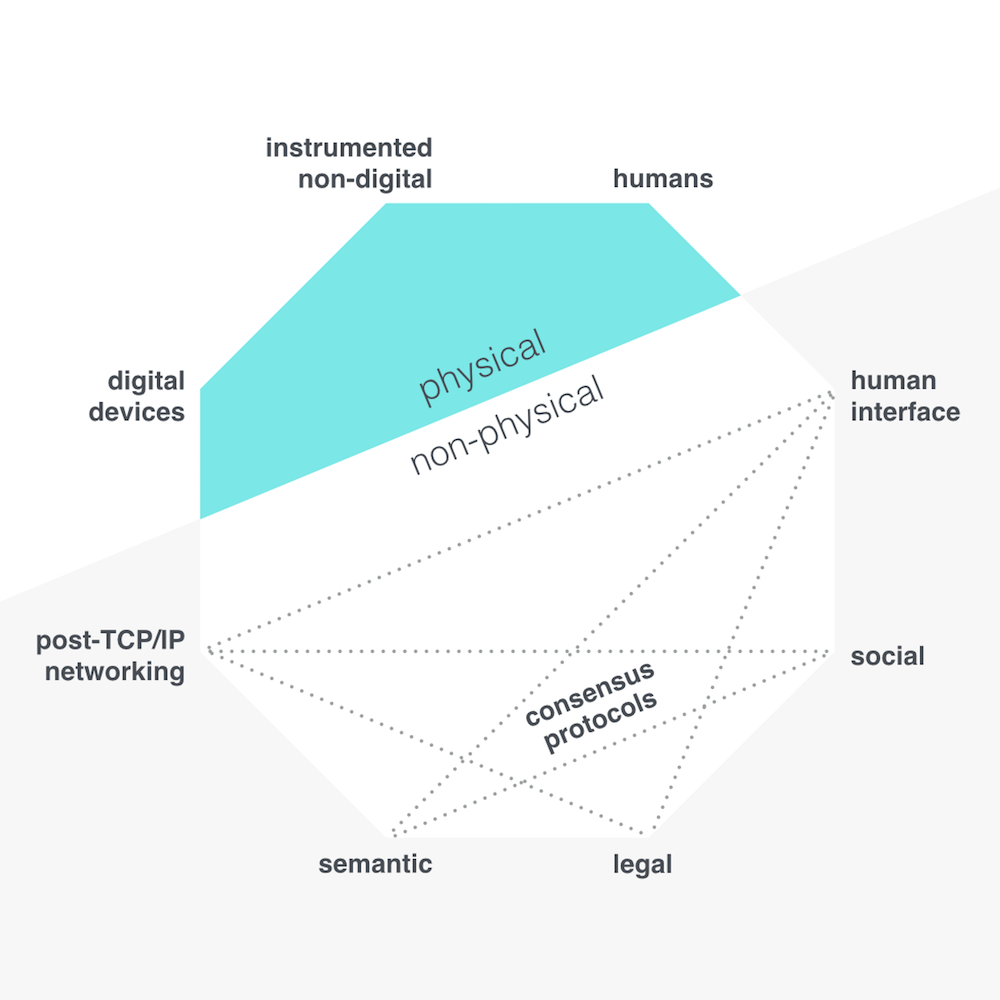
The physical
Humans, digital devices, and instrumented non-digital things
With human agency as my primary concern, it makes sense to start with humans. The current definition of a human is entirely within the physical realm, so sticking in that realm I immediately consider the connected things around us with which we interact. I determine two types – digital devices (eg, smart phones), and instrumented non-digital things (eg, our homes, our streets).
The primary functioning of digital devices is digital. Instrumented non-digital things on the other hand are those things that would exist in a non-digital sense but some advantage is sought with the integration of digital sensors. This distinction could be important when considering self-sovereignty (see below).
The non-physical
Reflecting on my two main themes – people and digital networks – we can dive into the non-physical from either the human or the digitalized physical realm. Let's start here from the latter.
Post-TCP/IP networking
Digital devices prove most potent when they are connected, so the next thing is the communications network. Today, we rely predominantly on the Transmission Control Protocol and the Internet Protocol (TCP/IP) but such reliance is problematic.
While IP was originally architected to effect the internet's distributed architecture, for various reasons of market dynamics and/or government policies, IP addresses or proxies to an IP address (in a system design known as network address translation) are available today only via decreasingly few internet service providers (ISPs) in their role as local internet registry. While there may be many brands in some markets vying for business, in reality there may be just two or three networks on the 'back end'. The majority of internet traffic in any given country goes through just a small handful of fixed line providers and cellular operators.
This means, for example, that when a government chooses to instigate mass surveillance of its citizens' Internet use (eg, the UK's so-called snoopers charter), contrary to their human rights (article 12 of the Universal Declaration of Human Rights), the government in question needs only require a relative tiny number of companies to do its work for them. (Such thinking may be sincere, even heartfelt, but that doesn't make it less flawed.)
The Internetome does not then reference TCP/IP but rather post-TCP/IP networking. A candidate approach could be named content networking, which employs unique identifiers based on what a resource is rather than where it is. Resources are more distributed and it becomes much harder to track who accesses what.
Now, how do you make sense of it when you find it?
Semantic
Such context is provided by semantic technologies, and it's critical that such interpretive capability not be the domain of one or a few organizations. Sense-making must be distributed to attenuate a systematic scaling of bias or misinterpretation, deliberate or accidental.
I include machine learning and artificial intelligence (AI) more broadly. Saying that, I'm not entirely convinced that's appropriate ... AI feels like it could be qualitatively different in the context here. On the one hand, there are semantic technologies that facilitate the explicit expression of meaning (eg, this is a date and it's Bob's birthday), whereas on the other hand AI might work on a corpus to find meaning we don't yet know is 'in there'.
Regardless, the meaning and the intelligence must come to our data rather than have our data go to the intelligence. That's not to say personal data should reside in personal data stores – I see little need for them. Rather, we can still engineer for personal data to 'breathe' amongst other data to better facilitate its transformation into information and knowledge without relinquishing domain over it.
Legal
It's not just the semantics of content that counts in our society, but the semantics of behaviour too. How do we express which behaviours are acceptable and which are not and adjudge accordingly? This takes us into the legal domain. Many may consider the system of law to be very centralized – after all, much law is determined at the national and international scale – but I'm referring here to the adaptive interweaving of our social code and digital code.
A blockchain fan may shout "smart contracts!" at this juncture – software protocols designed to verify or enforce the performance of a contract. However, the application of devices formed in the context of Shannon's information theory to the behaviours of humans more used to interaction along the lines of Pask's conversation theory is undoubtedly problematic. Kieron O'Hara (2017) points out ways in which smart contracts might in fact be a dumb idea. If anything, the DAO debacle in 2016 demonstrated that consensus systems are sociotechnical, and I'm very much viewing the internet here as a sociotechnical system rather than merely technical as you'll have noted from the etymological choice of Internetome.
Social
And now then we're at social. Conversations. Relationships. Communities.
Social media has been a mainstream phenomena for more than a decade now and classic network effects have consolidated our online social attention to very few platforms indeed. More than a few social media projects with decentralized architecture have attempted to break this hegemony, but the gravity of the connection, comfort and convenience offered by the centralized platforms has proved too irresistible. This will continue to be the case in my opinion until a decentralized project plays to different and unprecedented network effects.
Some believe antitrust examination will come to the rescue, but if such scrutiny hinges on consumer detriment then a defense may be constructed based on delivery of quite the opposite despite the deep but what some might dismiss as 'mere' philosophical concerns.
The troubles of fake news and filter bubbles have filled mainstream media in recent times, but this isn't the space to expand on all the chilling effects of such centralization. I'll limit myself to just one reference.
Couldry (2014) posits that the success of some social media services – he refers to Facebook – is based not just on connecting us to our immediate friends and family, but by invoking a broader ‘we’, a collectivity extending way beyond our immediate network. In making this broader connection, the service is setting itself up as the arbiter of what’s happening, what’s trending, and so, importantly, by accumulation, what matters. By corollary, the user is discouraged at best and disempowered at worst from making this assessment herself.
The human interface
Couldry's observation is the perfect segue to the last Internetome vertex – in terms of my discussion here rather than any particular order – the human interface.
User interface (UI) is a more common term, and appropriately so when the interface in question treats the person as a mere user or indeed a used-by. You are used by services hungry to construct services from your behaviours, your movements, your data, and eager to use you as their interface into the world.
If you do not have domain over the interface into and onto the digital fabric of the world around you, by definition some other party does. And the medium is the message. In other words, to design your experience is to control your experience, including what you will not experience.
Citing Deleuze (1992), Benjamin Bratton (2015) describes the emergence of a new control structure, “for which anyone’s self-directed movements through open and closed spaces is governed in advance at every interfacial point of passage” algorithmically, an evolution “marked by the predominance of computational information technology as its signature apparatus.” More prosaically, that public space in your local community that you love is already partly privatized. Sure, it remains public in the physical sense, but the physical and digital are enmeshed inseparably and your interface onto and into your surroundings while sitting on that park bench is in private hands today.
Foucauldian disciplining is in play, a conditioning process whereby individuals are nudged into aligning their behaviours with the interests of the source of power wielding the disciplining strategy. I haven't yet used the word dystopia, but I have now.
The human interface project – the hi:project – seeks to supplant the user interface.
Jef Raskin (2000), a human-computer interaction expert who conceived and started Apple’s Macintosh project, defines the interface as follows:
The way you accomplish tasks with a product – what you do and how it responds – that’s the interface.
The hi:project defines the UI specifically:
The way a machine or service helps you accomplish tasks with or through it, that’s the user interface.
What some refer to as the 'personal assistant' (eg, Google Assistant, Amazon Alexa), the hi:project calls the surveillance interface.
The way a machine or service surveils, records, interprets and to some degree controls as much as it can about your life to help you accomplish tasks with or through it, for the profit of the service provider, that’s the surveillance interface.
And finally:
The way your software helps you accomplish tasks with other software, that’s the human interface.
You will notice that our journey around the Internetome is complete – we're back to humans.
Tech We Trust: self-sovereignty + ourtech
UPDATE July 2021: The following description hints at the tension between "self" and "our". In more recent work, I have been highly critical of the founding principles of self-sovereign identity in particular, a foundation of self-sovereign technology — see the generative identity website.
The hi:project is an example of self-sovereign technology. Self-sovereign technologies are designed with just the one master in mind, the individual defined digitally by a self-sovereign identity.
Devon Loffreto (2012) defines sovereign source authority (the erstwhile turn of phrase) as “the actual default design parameter of human identity, prior to the ‘registration’ process used to inaugurate participation in Society.” He contends that the societal registration of birth currently eliminates self-sovereign identity and replaces it with an identity in society’s gift, asserting that this is a denial of the basic human right to self-declare participatory structure and authority; “Government is not formed to manage this process, but to be managed by this process.”
Descartes didn't say ‘I have a birth certificate, therefore, I am.’
Not everything can be (re)configured as self-sovereign technology, but nor need it be. I made the distinction between digital devices and the instrumented non-digital above as I doubt the latter may be designed as self-sovereign but will rather be accessed 'through' self-sovereign technology as appropriate.
Self-sovereign technologies are a step along the path to the redefinition of the human as biological, psychological, informational (Floridi 2005), and interfacial, but it remains that no person is an island – we will continue to interact with others and the world around us of course.
Identity, relationships, and information are fundamentals of organization (Wheatley, 1999) and identity is followed closely by both relationships and information as fundamentals of self-sovereignty. Everything in-between is co-operating (or, less optimistically, finding cause not to). I've attempted a diagram accordingly. It's far from perfect but I include it here in the hope it might inspire someone with greater graphical communication skills.
It references the idea of Tech We Trust, defined by the Digital Life Collective as those technologies that are equitable and accessible, putting our autonomy, privacy and dignity first.
Self-sovereign technologies are a subset of Tech We Trust, with the latter also extending out into the world in the form of technologies that aid our interactions and co-operation. (The Digital Life Collective is a co-operative, as a quick aside.) Many may consider my tech the ultimate response to their tech, but the Collective recognizes its redundant isolation. It's actually ourtech that matters. Self-sovereign tech is qualified by its ability to enable and be enabled by ourtech.

Consensus protocols
There's one further feature of the Internetome linking the non-physical vertices – consensus protocols. In short, such protocols set out to secure agreement among a number of decentralized processes / agents. Blockchains are perhaps the most famous type of consensus protocol.
Before the advent of consensus protocols one could have a centralized, incorruptible database, or a decentralized, corruptible one. Now we have the prize of both decentralization and incorruptibility, and a systematization of such protocols may be called a cryptonetwork given their cryptographic basis.
Cryptonetworks glue things apart.
The corresponding engineering is not straightforward, especially when taking into account my comments above regarding the sociotechnical imperative otherwise known as good governance.
To the title of this blog post – decentralization needs cryptonetworks, but clearly decentralization needs more than cryptonetworks. They offer resolution to a major engineering challenge, now we just need to crack on with the rest.
###
This post is based in part on a report submitted May 2017 in the process of my research at the University of Southampton.
Bratton, B.H., 2015. The Stack: On Software and Sovereignty. MIT Press.
Couldry, N., 2014. Inaugural: A necessary disenchantment: myth, agency and injustice in a digital world: A necessary disenchantment. Sociol. Rev. 62, 880–897. doi:10.1111/1467-954X.12158
Deleuze, G., 1992. Postscript on the Societies of Control. October 59, 3–7.
Floridi, L., 2005. The Ontological Interpretation of Informational Privacy. Ethics Inf. Technol. 7, 185–200. doi:10.1007/s10676-006-0001-7
Huxley, A., 1937. Ends and Means: An Inquiry Into the Nature of Ideals and Into the Methods Employed for Their Realization. Transaction Publishers.
Levy, S., 1984. Hackers: Heroes of the Computer Revolution. Anchor, Garden City, N.Y.
Loffreto, D., 2012. What is “Sovereign Source Authority”? Moxy Tongue.
McLuhan, M., 1962. The Gutenberg Galaxy: The Making of Typographic Man. University of Toronto Press.
Negroponte, N., 1995. Being digital. Vintage Books.
O’Hara, K., 2017b. Smart Contracts-Dumb Idea. IEEE Internet Comput. 21, 97–101.
Raskin, J., 2000. The Humane Interface: New Directions for Designing Interactive Systems. Addison-Wesley Professional.
Schumacher, E.F., 1973. Small Is Beautiful: A Study of Economics as if People Mattered. Harper, New York.
Wheatley, M., 1999. A Simpler Way. McGraw-Hill Education.
Wiener, N., 1950. The Human Use Of Human Beings: Cybernetics And Society. Houghton Mifflin.
Giuseppe L. says:
Hi Philip :)
Just two cents from my side to suggest how thousand-year-old semantics (i.e. each lemma in each language or dialect) is whole-heartedly rooted into cultures, hence in relations among humans.
My second point (again re. linguistics) is about the way language(s) generate new words, i.e. neologisms.
They do it non-linearly, each time disastrously to any attempt to plan them.
Yes it is, language does use mathematical catastrophes to evolve — something very difficult to foresee, plan, govern, but very easy to use once new article landed on earth.
From shape-shiftings of fundamental pronouns in human ontologies as suggested in your article it seems we should need a whole new alphabet, ~tuning forks, ~syntony definition, ~supporting aether.
Nice day —g
18 January 2019 — 4:27 pm